Faire sa veille informationnelle à l’ère de l’IA générative
Il y a quelques mois, Hubert Guillaud publiait, dans le média Dans Les Algorithmes, un article sur l’abondance de contenus générés par IA sur le Web (le fameux IA Slop).
Quelques semaines plus tard, le média Next publiait une enquête sur les médias diffusant en partie ou exclusivement des articles générés par IA.
Récemment encore, la Chine mettait en place une mesure imposant d’étiqueter les contenus générés par IA, prétextant un besoin de lutter contre la désinformation.
Les techniques d’Intelligence Artificielle générative sont aujourd’hui massivement utilisées pour publier du contenu sur la toile et il devient difficile de déterminer si une information est réelle ou non.
C’est pourquoi nous vous proposons un article permettant d’explorer quelques pistes pour faciliter l’exercice de l’esprit critique !
Bonne lecture !
En quoi la généralisation de l’IA générative nuit à la qualité des informations ?
IA Générative et réalité
L’IA générative (parfois abrégée GenAI) est une technique d’intelligence artificielle ayant pour objectif de produire du contenu qui semble naturel.
Ce qui marque quand on expérimente avec une IA générative, c’est la vraisemblance des réponses : celles-ci nous semblent plausibles.
Pourtant, une IA générative n’a aucune compréhension du réel, de ce qui existe ou non, de ce qui est donc vrai, ou non. Quand on lui demande « Qui est Framasoft ? », celle-ci va faire des calculs complexes et énergivores pour tenter de deviner quel est le résultat le plus probable attendu, en se basant sur toutes les données à partir desquelles elle a été « entraînée ».
Le logiciel nous fournira ainsi une réponse, parfois juste, parfois à côté de la plaque, parce que son algorithme aura estimé que c’est le résultat le plus probable attendu.

L’IA est la réalité.
Parmi les gros problèmes de l’IA générative se situe l’incapacité à pouvoir décrire le cheminement de l’algorithme pour générer une réponse. Aucune IA générative ne peut, à ce jour, décrire ses sources ni indiquer pourquoi elle a préféré donner telle réponse plutôt qu’une autre. Nous nous retrouvons, au mieux, avec une chaîne de pensée et un score de probabilité et au pire, avec seulement le contenu de la réponse. À nous alors de faire preuve d’esprit critique pour déterminer si l’IA générative a donné une réponse probable et juste ou probable mais fausse. À nous aussi, comme le décrit Hubert Guillaud dans son article, de douter de la machine pour ne pas nous laisser induire en erreur.
Nous n’en sommes pas habitué·es, pourtant.
En effet, nous avons plutôt tendance à croire aveuglément les machines, persuadé·es que nous en maîtrisons de bout en bout tous les processus. Or, l’IA générative, malgré son ton toujours sûr, sa verve parfois moralisatrice et son incapacité à dire « Je ne sais pas », n’est pas une technique dont nous maîtrisons tous les processus (de la construction à la réponse). Il y a des zones d’ombre, des zones incomprises (du fait de l’essence même de cette technique) qui nous empêchent de pouvoir faire confiance en ses affirmations.
Enfin, l’IA générative inverse notre rapport à la production (d’écrits, notamment). Si autrefois, il était plus long de produire un contenu textuel que de le lire, c’est aujourd’hui l’inverse et ce fait, qui peut sembler anodin de prime abord, transfigure pourtant une bonne partie de notre société, notamment numérique.
IA Slop
Depuis quelques temps, le terme de « Slop » ou d’ « IA Slop » devient de plus en plus populaire pour décrire les contenus de mauvaise qualité réalisés via IA générative et qui pullulent désormais sur le Web.
Le Web, avec l’IA générative, se remplit peu à peu de contenus vides de sens, entièrement pensés pour créer de l’engagement ou plaire aux algorithmes de SEO (Search Engine Optimisation, les techniques mises en place pour être mieux référencé·e sur Google).
L’objectif final étant d’engranger facilement des revenus, via les mécanismes de réseaux sociaux ou la publicité.
La surabondance de ces contenus a plusieurs effets :
• La raréfaction de contenus « originaux » (créés par un·e humain·e).
• Une tendance à la réduction de la qualité des résultats de l’IA générative. Les données générées par IA générative écrasant sous leur masse celles créées par des humain·es, ces dernières deviennent donc plus difficiles à retrouver en bout de chaîne.
• La mise en place d’un environnement « douteux ». Il devient difficile, aujourd’hui, de faire confiance en la qualité réelle d’un contenu a priori.
C’est en réaction à cette vague d’IA Slop et après la lecture de cette excellente enquête de Next sur la présence de plus de 3000 médias français générés par IA que nous avons décidé d’écrire cet article, dont le but est d’aider à mettre en lumière la problématique, mais aussi de présenter des pistes de solution.
Nous y reviendrons plus bas !
Comment reconnaître un texte produit par une IA Générative ?
Dans son enquête sur les sites de médias dont les contenus sont des plagiats générés par des IA génératives, Next a élaboré une méthode pour pouvoir reconnaître ceux-ci et nous la partage dans un article dont nous reprenons ici quelques points (mais nous vous recommandons chaudement de lire l’article de Next pour en découvrir l’intégralité des éléments) !
• ChatGPT a des « tics de langage » et utilise, abusivement, certains termes tels que « crucial », « fondamental », « captivant », « troublant », « fascinant », « besoin urgent », « il est essentiel », etc ;
• Les contenus produits par l’IA générative sont très scolaires alors que les journalistes tendent à adopter un « angle », c’est-à-dire un choix particulier dans la manière de traiter le sujet, aidant à se démarquer de ce qui est déjà écrit ;
• Les fins d’articles générés par ChatGPT résument souvent l’article et/ou abordent des conclusions moralisantes ;
• Les images d’illustration sont le plus souvent des copiés-collés des articles plagiés, parfois modifiés avec une rotation à 180° pour éviter d’être détectées par des moteurs de recherche d’images inversés. Sinon, elles sont générées par des IA génératives et sont particulièrement grossières et caricaturales, ou n’ont rien à voir avec le sujet ;
• …
La méthodologie de Next permet de nous outiller pour exercer notre esprit critique dans notre navigation quotidienne.
Cependant, cela peut rapidement être fastidieux, notamment avec l’immense quantité d’articles générés par IA générative auxquels nous sommes confronté·es au quotidien. Dans son enquête, Next souligne d’ailleurs que des milliers d’articles mis en avant par Google Actualités sont en fait le fruit d’IA génératives.
Afin de faciliter la reconnaissance des sites proposant des articles générés par IA, Next a développé une extension de navigateur permettant d’afficher un message d’information lorsque nous accédons à un site GenAI. L’extension est actuellement capable de reconnaître plus de 3000 sites ( !) et sa base de données continue de grossir.
Gardons cependant à l’esprit que si cette extension nous pré-mâche énormément le travail, elle ne suffit cependant pas pour nous permettre de lever notre vigilance. De nouveaux sites émergent chaque jour et l’extension ne peut tous les recenser.
Notons qu’il existe des outils pour détecter si un texte a été écrit par un humain, comme le détecteur de QuillBot ou GPTZero. Cependant, nous ne recommandons pas leur usage (ou du moins pas sans un regard très critique).
Premièrement, ces outils ne sont pas libres, il convient donc de ne pas y envoyer de textes privés ou sensibles. Mais surtout, ces détecteurs sont réputés pour leur manque de fiabilité.
Par exemple, OpenAI proposait un détecteur de textes générés par ChatGPT jusqu’en 2023, mais a décidé de l’arrêter, car il produisait trop d’erreurs.
Beaucoup de textes écrits par des humain·es peuvent être marqués par erreur comme générés par une IA. Ces détecteurs ont tendance à défavoriser les locuteurs et locutrices non-natives : les textes en anglais écrits par des personnes dont l’anglais n’est pas la langue maternelle seront plus souvent marqués à tort comme étant écrits par une IA. Et inversement, il existe de nombreuses techniques pour contourner ces détecteurs.
Par exemple, des chercheur·euses ont montré qu’il est possible de paraphraser un texte généré par une IA afin que le texte soit marqué comme écrit par un·e humain·e.
Si nous décidons quand même d’utiliser ces outils, ne nous fions pas à leur décision ou à la probabilité affichée. Remettons-les en perspective avec d’autres éléments, dont ceux mentionnés précédemment.
Sinon nous risquons d’accepter un texte écrit par une IA.
À l’inverse nous risquerions de jeter le discrédit sur un texte écrit par un·e humain·e, ce qui peut être embêtant, en particulier dans le cas des enseignant·es corrigeant des copies d’élèves.
De l’importance de la confiance
Il n’y a pas de méthode stricte et infaillible pour déterminer si un média est de source fiable ou non.
Au final, nous nous basons avant tout sur la confiance qu‘il nous inspire.
Et justement, il n’est pas toujours aisé de déterminer si nous souhaitons faire confiance ou non en un média.
Quelques questions peuvent néanmoins nous aider à affiner notre perception.
Quel est l’objectif du média ?
Se questionner sur l’objectif du média que l’on consulte peut grandement aider à y voir plus clair.
Pourquoi est-ce que celui-ci a été créé ?
Est-ce pour le « bien commun », un intérêt financier ou encore de pouvoir ?
Aucun média n’est totalement objectif, ce qui est normal, mais quel est le positionnement politique du média ?
Cherche-t-il à convaincre plutôt qu’informer ?
Quels sont les engagements du média pour parvenir à l’objectif évoqué ?
Parfois, certains objectifs peuvent n’être que des vœux pieux.
Regarder concrètement quels sont les actes et les engagements mis en place du média pour faire advenir ces objectifs peut nous aiguiller à jauger le degré de confiance que nous donnerons à celui-ci.
Qui possède le média ?
Et donc, quels sont les intérêts des personnes qui possèdent le média ?
Et quels pouvoirs exercent ces personnes sur lui ?
La cartographie mise à jour chaque année par Le Monde Diplomatique et ACRIMED est édifiante sur le fait que la majorité des médias « mainstream » sont — au moins en partie — possédés par des milliardaires ou des groupes de milliardaires.
Ces derniers semblent pouvoir orienter les journaux dans certaines directions, comme encore récemment avec Jeff Bezos (patron de, entre autres, Amazon, Twitch ou le Washington Post, quotidien emblématique étasunien), qui a souhaité ne pas faire publier la traditionnelle recommendation de vote du journal à l’approche de l’élection présidentielle étasunienne (alors que cette recommandation allait dans le sens de Harris, l’opposante de Trump).
Cependant, s’il est possible que les médias possédés par les milliardaires soient, en partie, influencés par leurs dirigeant·es, ce n’est pas forcément systématiquement le cas.
Le Monde Diplomatique, par exemple, est possédé à 51 % par le groupe Le Monde, mais à 49 % par l’association de lecteurs et lectrices du journal et l’association composée de toute l’équipe de rédaction. Ce sont ces 49 % qui choisissent le ou la rédacteurice en chef et iels possèdent un droit de veto pour les décisions prises.
Nous y retrouvons là un exemple de contre-pouvoir.
Comment est financé le média ?
Dans une société capitaliste, l’argent est au cœur de bien des choses et nous pensons essentiel de nous questionner sur la manière dont un média est financé.
Est-ce via la publicité ?
Sont-ce les liens d’affiliation (permettant de récolter des sous en fonction du nombre de visites/d’achats sur le lien) ? Les abonnements ? Les aides de l’État ? Les dons ?
Et si c’est un peu de tout ça, dans quelles proportions ?
Il y a bien des manières de financer un média, et toutes ne sont pas forcément viables dans le long terme ou ne correspondent à notre propre idée de la déontologie.
Le média cite-t-il ses sources ?
C’est une des premières choses que nous cherchons en général à consulter : d’où vient l’information mise en avant dans l’article.
Est-ce que c’est une revue scientifique ? Une dépêche AFP ? Un autre journal ? Un vieux Skyblog fait par Camille Dupuis-Morizeau ?
Si — comme trop souvent à notre goût 😬 — les sources ne sont pas citées, il est difficile de prouver la véracité de l’information et il nous faudra chercher celles-ci nous-même.
L’article est-il relu par les pair·es ?
C’est un processus obligatoire dans beaucoup de médias, chaque article est supposé être relu par au moins une autre personne que l’auteur·ice.
Cela permet d’avoir un regard frais sur le sujet, sur la qualité de l’article, etc.
Cependant et évidemment, la relecture n’empêche pas toujours certaines erreurs ou une ligne éditoriale idéologique.
Parfois, nous sommes convaincu·es que l’angle adopté par un article est le bon alors que d’autres estimeront que non.
D’autres fois, nous aurons tout simplement fait une erreur : choisi une source peu fiable, mal interprété une situation, etc.
Les erreurs arrivent et c’est pourquoi le processus de relecture et validation par d’autres existe !
Il y a-t-il une mise en avant des corrections apportées à l’article ?
Comme les erreurs arrivent, il est courant d’apporter des corrections aux articles publiés.
Est-ce que le média met en avant (en haut de son article, voire même en fin) ces corrections ?
Une mise à jour de l’article suite à l’apparition d’un événement nouveau mais crucial à la compréhension du sujet, par exemple ?
Toutes ces questions ne constituent pas une liste exhaustive, bien sûr, mais celles-ci peuvent déjà grandement nous aider à nous positionner vis-à-vis d’un média.
En nous prêtant à l’exercice, nous nous rendrons compte qu’il est parfois difficile de savoir clairement si un média est de confiance et nous devrons donc faire preuve de vigilance à son égard.
Enfin, aujourd’hui, avec la quantité faramineuse de sites générés par IA, nous ressentons facilement un sentiment de submersion et l’énergie nécessaire pour pouvoir exercer notre esprit critique sur tous ces sites dépasse l’entendement.
Faire sa veille, à l’heure de l’IA générative, est un vrai défi !

L’exercice de l’esprit critique à l’heure de l’IA, une entreprise difficile.
C’est pourquoi dans la dernière partie de cet article, nous vous proposons de découvrir un outil pouvant aider à faciliter la veille informationnelle !
Vigilance cependant, si cet outil technique peut aider à assumer notre veille, il nous demande tout de même de rester attentifs et attentives, notamment avec la fonctionnalité de veille partagées !
Découvrons cet outil ensemble !
Flus, outil de veille simple
Flus est un outil de veille conçu par Marien, membre de Framasoft.
Ce n’est pas le premier coup d’essai de Marien dans la conception d’un tel outil, il a en effet, en 2012, initié un autre projet de veille : FreshRSS.
C’est grâce à l’enseignement des expériences apprises en concevant FreshRSS qu’il a pu concevoir une expérience aussi fluide dans Flus.

Liste des services proposés par Flus.
Au cœur de FreshRSS et Flus se situe une technique majeure du Web : les flux RSS.
C’est quoi un flux RSS ?
Les flux RSS existent depuis 1999 et permettent à des applications tierces de savoir, presque en temps réel, si un nouvel article a été publié sur notre site.
![]()
Le gros avantage est de pouvoir centraliser dans un unique logiciel tous les flux auxquels nous souhaitons nous « abonner » et donc prendre connaissance des mises à jour de dizaines (voire centaines ou milliers, c’est à nous de choisir) de sites sans avoir à les ouvrir individuellement !
Le flux RSS est une technique légère, simple, mais terriblement efficace, simplifiant énormément le processus de veille.
C’est grâce aux flux RSS que de nombreux outils de veille fonctionnent… dont Flus !
Flus : un outil pensé pour éviter d’être submergé·es d’informations
Une des problématiques auxquelles nous pouvons être confronté·es en regroupant des centaines de flux RSS dans un logiciel permettant de les lire (ces logiciels sont appelés des agrégateurs) est que nous pouvons nous sentir submergé·es d’informations.
Si nous nous abonnons à des sites qui publient beaucoup d’actualités ou si nous avons beaucoup d’abonnements, il est fréquent de ressentir une forme « d’info-pollution ».
C’est pourquoi Flus a été pensé avec deux fonctionnalités nous permettant de contrôler le flot d’informations auquel nous sommes confronté·es.
Premièrement, l’espace de lecture des flux est conçu pour ne pas laisser s’accumuler les contenus, évitant ainsi une surcharge d’informations. Cet espace est limité volontairement à 50 contenus qui doivent être traités (ex. marqué comme lu, rangé, ou retiré) avant de pouvoir passer à la suite.
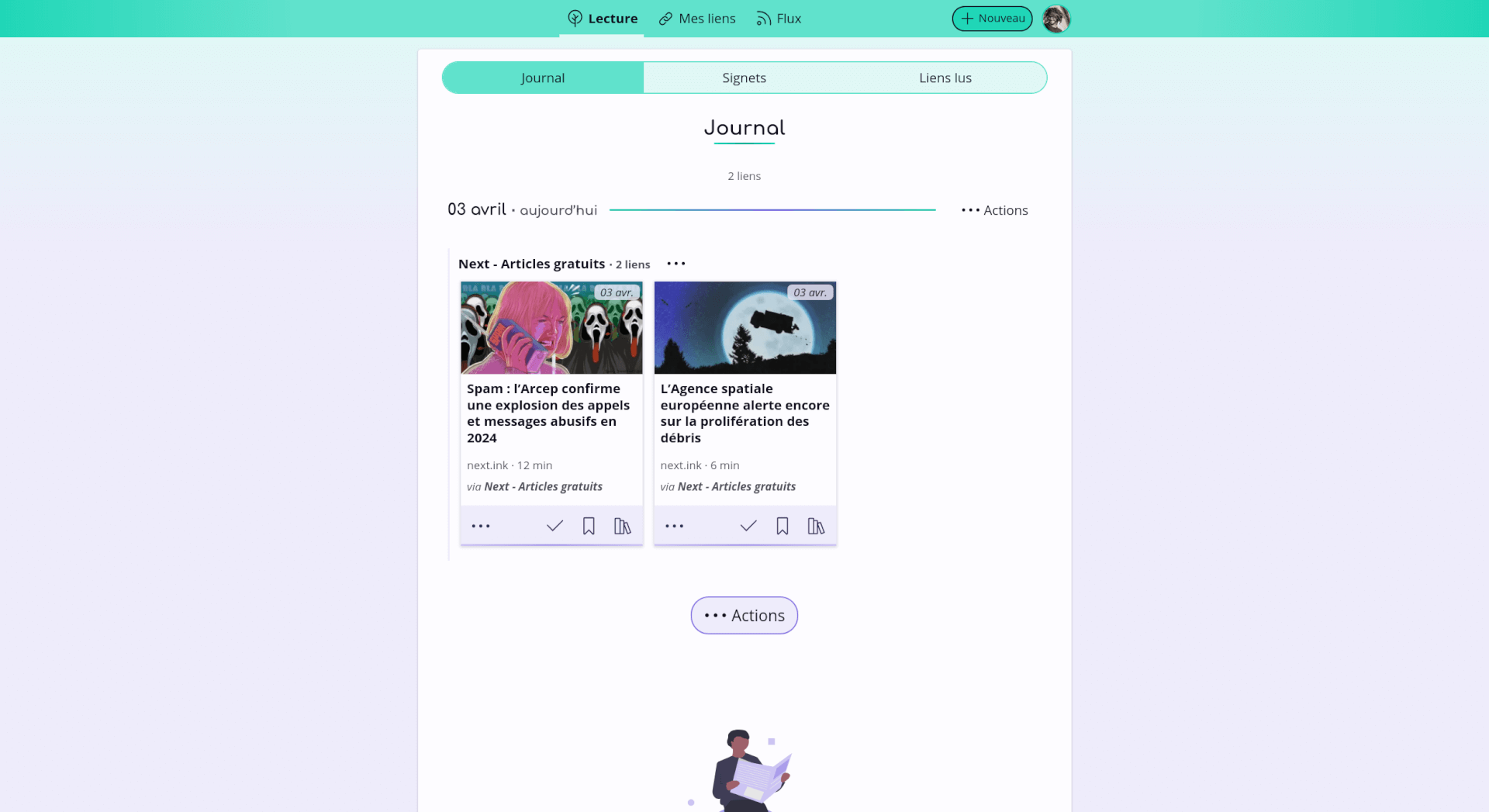
Capture d’écran du journal de Flus.
Deuxièmement, chaque flux dispose d’un indicateur de fréquence de publication, indiquant le nombre de liens postés chaque jour.
Si ce rythme est trop élevé, il est possible de configurer le filtre définissant sur quelle période Flus va récupérer les publications pour l’abonnement.
Ce dernier point est très utile et est configuré par défaut pour ne récupérer que les publications de la dernière semaine. Cependant, si nous souhaitons tout recevoir d’un flux RSS, il est possible de configurer celui-ci pour tout nous afficher, sans limite temporelle.
Un outil de veille collaborative
Autre aspect intéressant de Flus : la possibilité de partager sa veille avec d’autres ou de construire des veilles collaboratives.
Le site propose d’ailleurs, dans son interface, de découvrir la veille d’autres personnes, triées par catégories.
Cette fonctionnalité est bien chouette lorsque l’on cherche à sortir un peu de ce que l’on connaît et chercher à découvrir d’autres sites ou sujets.
Attention encore ! Ce n’est pas parce que quelqu’un publie sa veille sur Flus que les informations partagées sont forcément fiables.
Là aussi, nous devons trouver où placer notre confiance !
Un modèle de financement basé sur la solidarité
Flus utilise un modèle de financement basé sur le prix libre.
Le principe est simple : vous pouvez profiter de Flus au prix qui vous convient, y compris gratuitement. Cela permet à ses utilisateurs et utilisatrices de participer au fonctionnement de la plateforme à hauteur de leurs moyens.
Afin d’avoir une idée de ce que peut être une contribution financière juste, Marien affiche trois tarifs références : un tarif solidaire pour celles et ceux qui ne peuvent offrir plus, un tarif équilibre qui correspond au juste prix et un tarif soutien qui correspond à l’objectif financier de l’auteur.
Alors que l’IA générative transforme agressivement le Web en un immense catalogue de contenus approximatifs, conçus par des IAs pour plaire à des algorithmes (principalement ceux du moteur de recherche de Google), la société capitaliste nous demande toujours plus d’efforts pour réussir à exercer notre esprit critique.
Pourtant il existe encore des espaces de respiration, où nous pouvons relâcher (un peu) notre attention, et des outils nous permettant d’y accéder plus facilement.
Le flux RSS est un outil émancipateur d’une rare simplicité qui, grâce à des plateformes comme Flus ou des outils comme FreshRSS, nous permet de décider de la manière avec laquelle nous nous confrontons aux informations de ce monde.
Alors profitons de ces joyaux techniques pour partager nos veilles, créer des veilles collectives, exercer ensemble notre esprit critique et lutter, solidairement et joyeusement, contre la désinformation en ligne !